背景
数据挖掘的工程师都知道,短文本数据在我们的生活中无处不在。只要我们上网,我们都会遇到形式多样的短文本,比如文本广告、图片标题、微博、优酷视频、豆瓣评论、短信、百度知道里的提问和回答。
数据挖掘中的内容分析任务,就是要从这些海量的短文本数据中提取出精准的主题,并为后续的内容识别分类、用户建模画像、意图识别、热点话题爆发检测等任务提供良好的数据基础。
尽管在文本分析领域已经有成熟的数据挖掘方法,但是针对短文本的主题挖掘还是存在很多技术瓶颈。
传统的文本主题挖掘方法比如plsa、lda方法,都假设了一篇文章的内容有多种主题混合而成,并且每个主题都有各自不同的权重,占主导地位的主题就体现了一篇文章的主旨。但是,这些传统的文本建模技术提出的时候,就是针对文档层面的词语共现模式进行设计的,在运用到短文本数据的时候就遇到了严重的稀疏性问题。在长文本数据中,有足够长的文字篇幅让这些传统技术学习到词语的共现关系,主题代表性强的词能够在文本中经常出现。但是在短文中,词语的wordcount并不能反映哪个词更重要。而且在短文本数据中,由于缺乏足够的上下文信息,这些传统技术对有多义词的鉴别能力更是大幅下降。
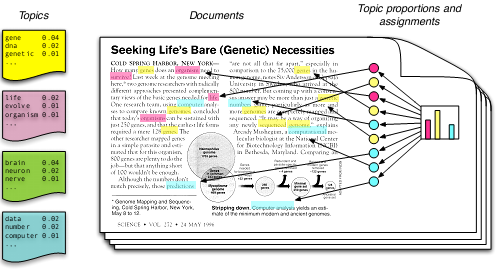
图1:lda文本模型
针对业务中遇到短文本垃圾评论数据,我们采用针对二元文法概率建模的btm模型(a biterm topic model for short texts,www2013)对数据进行主题建模和检测,在对”色情“-“辱骂”的短文本数据的分类问题中,相比传统的lda主题模型,得到了更好的分类效果。
传统的概率统计方法,本质上是在document层次上对词语的共现模型进行设计的。从而得到的主题,可以用这个主题相关的词语来表示。而在短文本问题中,在document的层次级别上反应的上下文信息较少,btm模型中,直接对bi-gram的双元文法的词语共现进行建模。btm模型中,将短文本中的每个词,看成是一定概率分布下随机生成的过程,直观地可以用概率图模型表示如下(请见图2)。在btm中,除了假设每一条文本数据的内容是由多种主题构成的,针对二元文法中共现的词语pair,两个词语也被设计成从同一个主题下的分布生成。
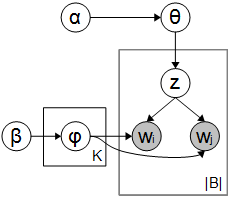
图2:btm的概率图模型
不同于传统的lda概率模型,btm短文本概率统计模型的数据生成过程设计如下:
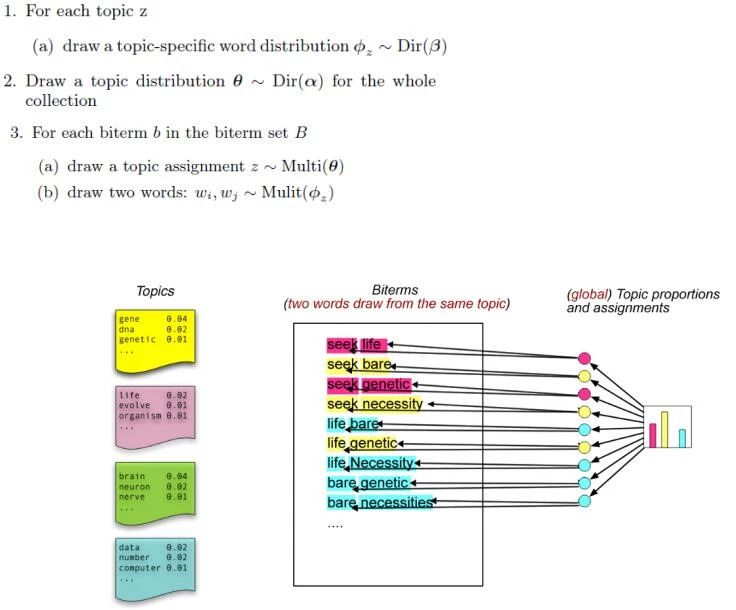
图3:btm文本模型
值得一提的是btm模型直接对二元文法中的词语进行概率分布下的随机生成,而不是对文档document进行建模,因此文档的主题分布特征只能通过“贝叶斯定理”计算得到,
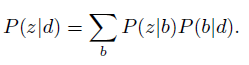
其中的
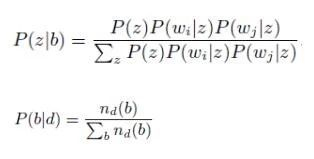
btm模型的训练学习过程如下:

其中每个轮迭代中,共现双词pair的主题的采样公式为:
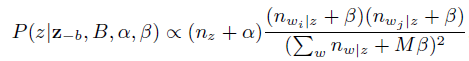
最后,迭代结束后,参数更新:
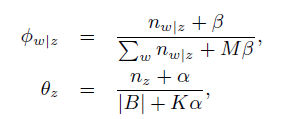
从以上模型设计可以看到btm的学习训练过程极为高效,模型参数学习相对于传统lda文本模型更为简单。
短文本内容检测性能测试分析
以下是业务中btm模型在短文本评论数据上对“色情”“辱骂”主题的分类检测流程:

图4:短文本数据内容检测流程
图5所示的是业务中处理的短文本数据经过预处理过滤、分词得到的样例数据。
图6所示的是短文本数据词频分布统计,分布情况基本和推荐系统的用户、商品的大数据分布类似,集中体现出长尾的现象。
图5:短文本数据
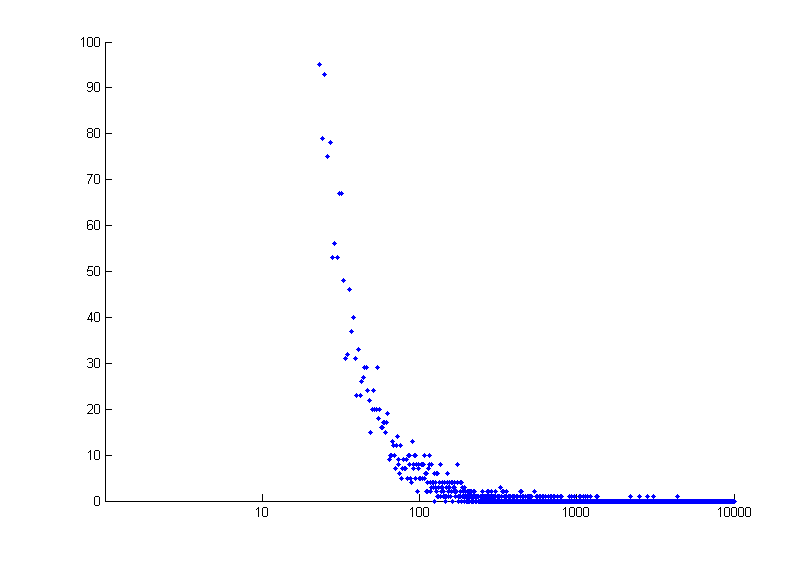
图6:短文本数据的词频分布统计
以下是对btm和传统lda在短文本数据内容检测识别任务上的性能比较。
图7是对两种文本模型在“色情”vs“辱骂”分类任务上的准确率(acc)性能比较,我们测试比较了btm和lda模型在不同topic主题个数下的性能变化曲线。
图8是对两种文本模型在“色情”vs“辱骂”分类任务上的auc性能指标的比较,我们同样测试比较了btm和lda模型在不同topic主题个数下的性能变化曲线。
图9是btm和lda文本模型在短文本数据分类(“色情”vs“辱骂”)上的auc性能曲线比较。
从结果中,可以看到btm在短文本主题学习上比传统的lda概率文本模型有明显的优势:不仅在acc和auc具体指标上btm有更好的效果,传统lda文本模型学习到的概率主题特征在topicnum>300之后,主题特征的同质化现象严重(短文本数据集的词稀疏性、主题稀疏性的影响较重),分类器训练和预测的时候,预测分数趋向集中,cv确定分类阈值变得困难,而且偏离0.5的中心值;实际经验情况,概率模型的先验参数需要尽可能调低,最优阈值分数确定在0.585左右。
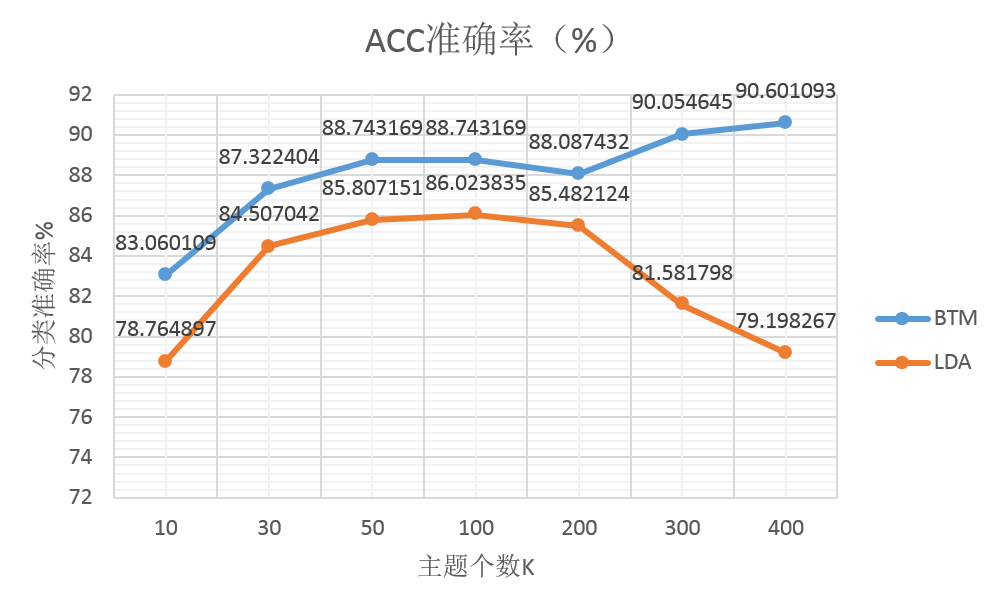
图7:btm与传统lda文本模型在短文本内容主题检测上的准确率(acc)比较
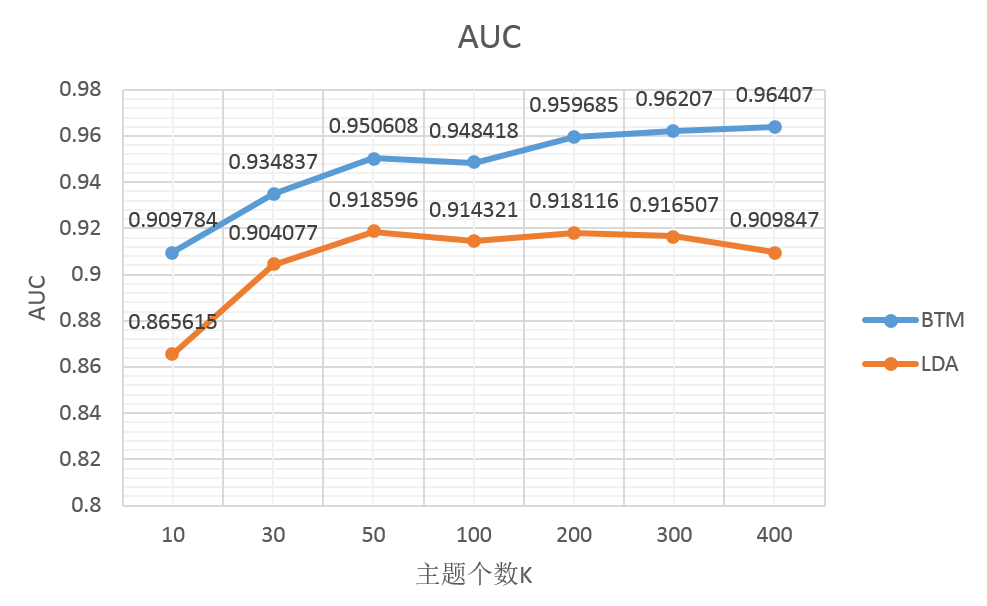
图8:btm与传统lda文本模型在短文本内容主题检测上的分类结果auc性能指标的比较
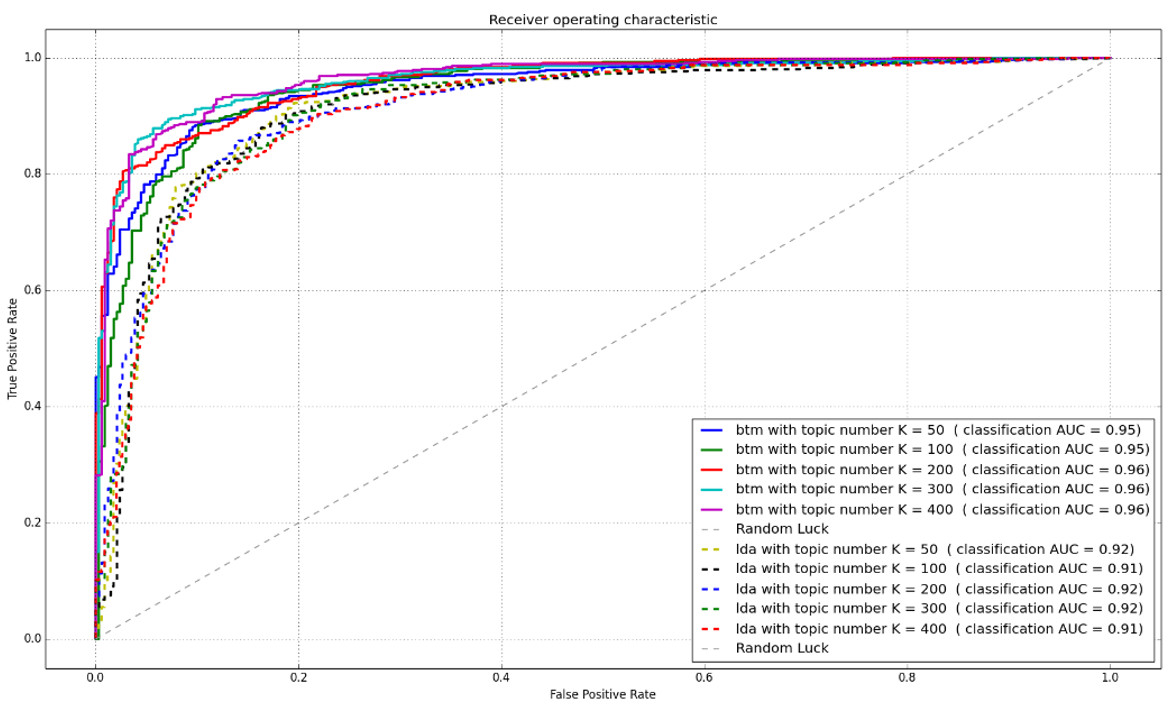
图9:btm和lda文本模型在短文本数据分类上的auc性能曲线比较
为了更直观的观察btm学习到的“语义主题”,我们打印出每个主题下的最具代表性的词语进行可视化描述。如图10所示,红色方框圈出来的“语义主题”具有明显的“色情”倾向性;蓝色方框圈出来的“语义主题”具有明显的“辱骂”倾向性。在图11-1和图11-2中我们选取了其中4个“语义主题”进行词云图的可视化,可以明显看到各个“主题”的语义倾向性。

图10:btm文本模型学习得到的“语义主题”结果

图11-1:词云图展示挖掘出来的偏辱骂的主题

图11-2:词云图展示挖掘出来的偏色情的主题
图12中我们分析了各个类别(“色情”vs“辱骂”)的随着主题个数k变化的检测性能曲线。可以看到分类检测的各个类别在精准度precision和召回率recall指标上都大体随着主题个数k的增加而稳定提高。
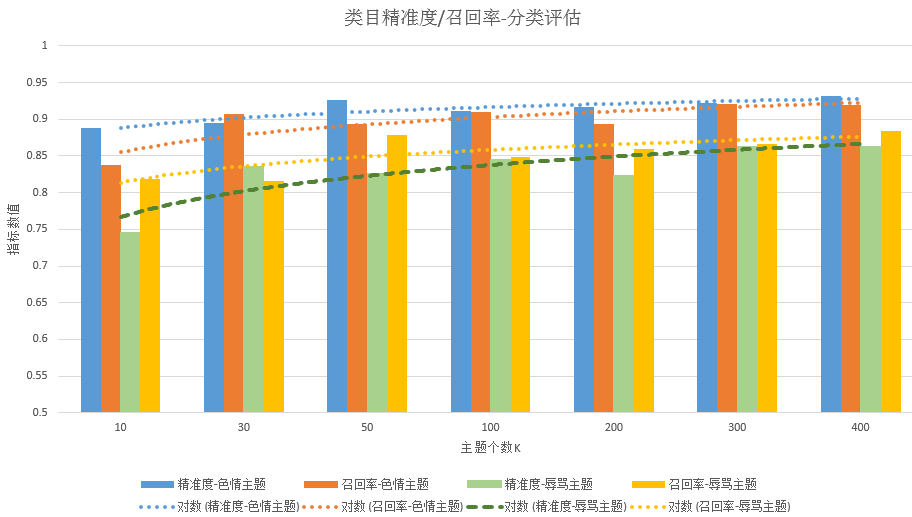
图12:各个类别检测结果随btm主题个数k变化的性能曲线(精准度precision、召回率recall)
总结
从短文本数据的内容检测的分类结果上看,btm相比于传统的lda文本模型克服了短文本数据的稀疏性问题的影响,学习得到更高质量的“语义主题”。
在短文本数据分类任务上btm比传统的lda文本模型在acc准确率和auc性能指标上都更高更稳定,相比于lda文本模型具有明显的优势(文/易盾实验室)。
以上,只是简单介绍了短文本内容安全检测其中一小块的技术,实际应用中,网易易盾采用了更加复杂的模型和多套组合拳。如果对内容安全检测能力要求比较高的客户,可以免费体验网易易盾高效、智能的内容安全服务。
相关阅读: